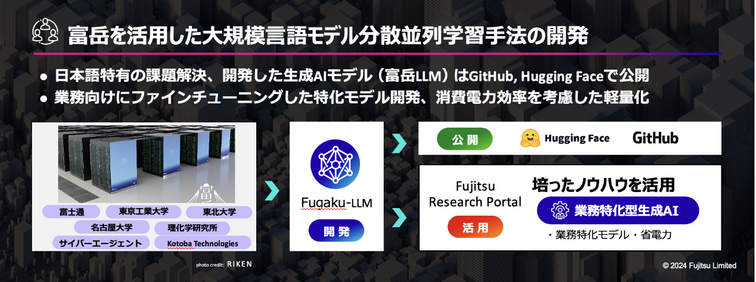
Deadlock detected! — HPC Research
"Docker containers are kind of neat. They are also kind of a craven surrender to the
rotting mess of excessive software complexity."
—John Carmack
"Docker containers are kind of neat. They are also kind of a craven surrender to the rotting mess of excessive software complexity."—John Carmack
Three Publication Highlights
|
F. Hoerold, I.R. Ivanov, A. Dhruv, W.S. Moses, A. Dubey, M. Wahib, J. Domke, "RAPTOR: Numerical Profiling of Scientific Applications," in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC ’25, (Piscataway, NJ, USA), IEEE Press, Nov. 2025; wins Reproducibility Advancement Award at SC25 | |
|
J. Domke, S. Matsuoka, I.R. Ivanov, Y. Tsushima, T. Yuki, A. Nomura, S. Miura, N. McDonald, D.L. Floyd, N. Dube, "HyperX Topology: First at-scale Implementation and Comparison to the Fat-Tree," in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC ’19, (Piscataway, NJ, USA), IEEE Press, Nov. 2019. | |
|
J. Domke, T. Hoefler, and S. Matsuoka, "Routing on the Dependency Graph: A New Approach to Deadlock-Free High-Performance Routing," in Proceedings of the 25th ACM International Symposium on High-Performance Parallel and Distributed Computing, HPDC ’16, (New York, NY, USA), pp. 3-14, ACM, 2016. |
Publications by Year
|
M. Besta, N. Blach, P. Iff, M. Schneider, A. Maissen, S.D. Girolamo, J. Domke, J. Krattenmacher, A. Singla, K. Lakhotia, F. Petrini, T. Hoefler, "EvalNet: A Practical Toolchain for Generation, Analysis, and Simulation of Large-Scale Networks," in Proceedings of the 40th IEEE International Parallel and Distributed Processing Symposium (IPDPS), (Piscataway, NJ, USA), IEEE Press, May 2026. (to appear) | |
|
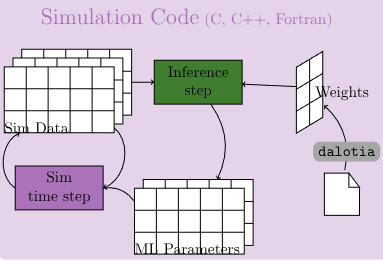
T. Pollinger, J. Domke, "High-performance in-situ ML Inference with dalotia: A Lightweight Tensor Loader API for Science Codes," in Proceedings of Supercomputing Asia and International Conference on High Performance Computing in Asia Pacific Region (SCA/HPCAsia 2026), Jan. 2026. (to appear) | |
|
R. Iwai, J. Domke, E. Vatai, Y. Sato, "Prototyping an Autotuning Framework for Program Optimization Using Exo Language," in Proceedings of the IWAHPCE workshop at Supercomputing Asia and International Conference on High Performance Computing in Asia Pacific Region (SCA/HPCAsia 2026), Jan. 2026. (to appear) | |
|
M. Xiao, I.R. Ivanov, J. Domke, T. Endo, "Bridge Over Troubled Water: Offloading OpenMP Regions to XLA via StableHLO," Poster presented at Supercomputing Asia and International Conference on High Performance Computing in Asia Pacific Region (SCA/HPCAsia 2026), Jan. 2026. (to appear) | |
|
T. Takahashi, J. Domke, S. Tomishima, "Can SOT-MRAM replace SRAM in modern HPC CPUs? -- A case study utilizing gem5 and STREAM," Poster presented at Supercomputing Asia and International Conference on High Performance Computing in Asia Pacific Region (SCA/HPCAsia 2026), Jan. 2026. |
|
K. Qi, K. Fan, J. Domke, S. Ba, V. Vishwanath, M. Papka, S. Kumar, "ML-Driven Auto-tuning Framework for Non-uniform All-to-All Data Exchange," in Proceedings of the 32nd IEEE International Conference on High Performance Computing, Data, and Analytics HiPC ’25, (Piscataway, NJ, USA), IEEE Press, Dec. 2025; wins Distinguished Paper Award | |
|
F. Hoerold, I.R. Ivanov, A. Dhruv, W.S. Moses, A. Dubey, M. Wahib, J. Domke, "RAPTOR: Numerical Profiling of Scientific Applications," in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC ’25, (Piscataway, NJ, USA), IEEE Press, Nov. 2025; wins Reproducibility Advancement Award at SC25 | |
|
D.D. Sensi, S. Pasqualoni, L. Piarulli, T. Bonato, S. Ba, M. Turisini, J. Domke, T. Hoefler, "Bine Trees: Enhancing Collective Operations by Optimizing Communication Locality," in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC ’25, (Piscataway, NJ, USA), IEEE Press, Nov. 2025. | |
|
I.R. Ivanov, J. Domke, T. Endo, J. Doerfert, "Dynamic Thread Coarsening for CPU and GPU OpenMP Code," in Proceedings of the SC '25 Workshops of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC ’25, (Piscataway, NJ, USA), IEEE Press, Nov. 2025. | |
|
S. Burak, S. Schwitanski, F. Tomski, J. Domke, M. Müller, "Extending the SPMD IR for RMA Models and Static Data Race Detection," in Proceedings of the EuroMPI/USA 2025, Charlotte, USA. | |
|
G. Accordi, J. Domke, T. Pollinger, D. Gadioli, G. Palermo, "Towards High-Performance and Portable Molecular Docking on CPUs Through Vectorization," in Proceedings of the 2025 IEEE International Conference on Cluster Computing (CLUSTER), (Edinburgh, UK), IEEE Computer Society, Sept. 2025. | |
|
F. Antici, A. Borghesi, Z. Kiziltan, J. Domke, A. Bartolini, "An Online Algorithm for Power Consumption Prediction of HPC Workload," In: Future Generation Computer Systems (Aug. 5, 2025), p. 108064 | |
|
F. Antici, A. Bartolini, J. Domke, Z. Kiziltan, K. Yamamoto, "F-DATA: A Fugaku Workload Dataset for Job-centric Predictive Modelling in HPC Systems," in Nature Sci Data 12, 1321 (2025) | |
|
M. Sander, J. Domke, "Compressing Large Language Models with ZFP: Lessons Learned," in Proceedings of the Workshop on the New Approaches to Addressing the Computing Requirements of LLMs and GNNs (LG-ARC 2025), co-hosted at the 52nd Annual International Symposium on Computer Architecture (ISCA '25),Tokyo, Japan, June 21-25, 2025. | |
|
J. Domke, M. Wahib, A. Dubey, T. Ben-Nun, E.W. Draeger, "A Unifying Framework to Enable Artificial Intelligence in High Performance Computing Workflows," In: Computing in Science & Engineering 27.01 (May 28, 2025), pp. 73–78. | |
|
K. Fan, J. Domke, S. Ba, S. Kumar, "Parameterized Algorithms for Non-uniform All-to-all," in Proceedings of the 34th ACM International Symposium on High-Performance Parallel and Distributed Computing, HPDC ’25, Notre Dame, USA, 2025. | |
|
F. Antici, A. Borghesi, J. Domke, Z. Kiziltan, "UoPC: A User-based Online Framework to Predict Job Power Consumption in HPC Systems," in ISC High Performance 2025 Research Paper Proceedings (40th International Conference) (ISC 2025), hamburg, Germany, June 2025 | |
|
C. Gavoille, H. Taboada, J. Domke, B. Goglin, E. Jeannot, "Performance Projection for Design-Space Exploration on future HPC Architectures," in Proceedings of the 39th IEEE International Parallel & Distributed Processing Symposium (IPDPS), (Milan, Italy), IEEE Computer Society, June 2025 | |
|
X. Chen, A.C. Zhou, D. Wu, P. Chen, E. Vatai, J. Domke, M. Wahib, "Optimizing Computed Tomography Reconstruction with Mixed Precision on Nvidia Jetson Devices," Poster presented at IEEE Symposium on Low-Power and High-Speed Chips and Systems 2025, COOL Chips 28, Tokyo, Japan, Apr. 2025 | |
|
I. Ivanov, J. Domke, T. Endo, J. Doerfert, "Minimal and Relocatable Proxy App Generation," Poster presented at ACM/IEEE International Symposium on Code Generation and Optimization, CGO '25, Las Vegas, USA, Mar. 2025; wins 3rd place CGO ACM Student Research Competition (SRC) |
|
W. Dawson, K. Ozaki, J. Domke, T. Nakajima, "Reducing Numerical Precision Requirements in Quantum Chemistry Calculations," in Journal of Chemical Theory and Computation, Vol 20/Issue 24, Dec. 2024 | |
|
R. Iwai, E. Vatai, J. Domke, Y. Sato, "Evaluation of Vectorization Methods on Arm SVE Using the Exo Language," Poster presented at IEEE Cluster 2024, CLUSTER '24, Kobe, Japan, Sept. 2024 | |
|
I.R. Ivanov, J. Domke, T. Endo, J. Doerfert, "Automatic Parallelization and OpenMP Offloading of Fortran Array Notation," in Proceedings of the Advancing OpenMP for Future Accelerators: 20th International Workshop on OpenMP, IWOMP 2024, Perth, WA, Australia, September 23-25, 2024 | |
|
S. Burak, I.R. Ivanov, J. Domke, M. Müller, "SPMD IR: Unifying SPMD and Multi-Value IR Showcased for Static Verification of Collectives," in Proceedings of the Recent Advances in the Message Passing Interface: 31st European MPI Users' Group Meeting, EuroMPI 2024, Perth, WA, Australia, September 25-27, 2024; wins Best Paper Award at EuroMPI/Australia 2024 (Rusty Lusk Award) | |
|
E. Vatai, J. Domke, B. Gerofi, Y. Kodama, M. Wahib, A. Podobas, S. Mittal, M. Pericas, L. Zhang, P. Chen, A. Drozd, S. Matsuoka, "A Case for 3D-Stacked Cache in HPC – Lessons Learned after Many Months of Simulations," Poster and lightning talk presented at ModSim 2024 Workshop on Modeling & Simulation of Systems and Applications, ModSim '24, Seattle, USA, Aug. 2024. | |
|
N. Blach, M. Besta, D.D. Sensi, J. Domke, H. Harake, S. Li, P. Iff, M. Konieczny, K. Lakhotia, A. Kubicek, M. Ferrari, F. Petrini, T. Hoefler, "A High-Performance Design, Implementation, Deployment, and Evaluation of The Slim Fly Network," in Proceedings of the 21st USENIX Symposium on Networked Systems Design and Implementation, NSDI'24, Santa Clara, USA, Apr. 2024 | |
|
I. R. Ivanov, O. Zinenko, J. Domke, T. Endo, W. S. Moses, "Retargeting and Respecializing GPU Workloads for Performance Portability," in Proceedings of the IEEE/ACM International Symposium on Code Generation and Optimization (CGO'24), Edinburgh, UK, Mar. 2024 |
|
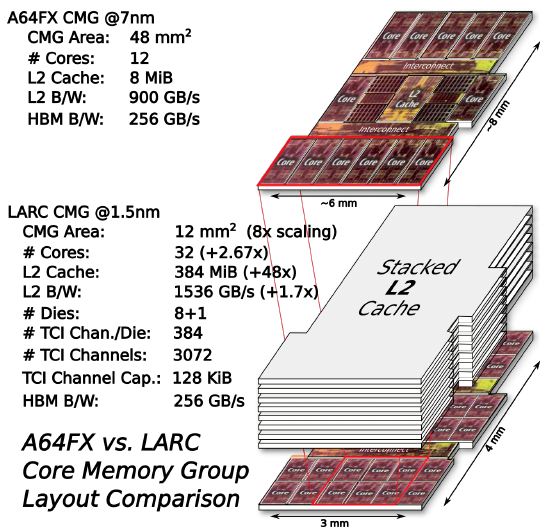
J. Domke, E. Vatai, B. Gerofi, Y. Kodama, M. Wahib, A. Podobas, S. Mittal, M. Pericas, L. Zhang, P. Chen, A. Drozd, S. Matsuoka, "At the Locus of Performance: Quantifying the Effects of Copious 3D-Stacked Cache on HPC Workloads," in ACM Transactions on Architecture and Code Optimization (TACO), vol. 20, pp. 1–26, Dec. 2023. | |
|
O. Pearce, A. Scott, G. Becker, R. Haque, N. Hanford, S. Brink, D. Jacobsen, H. Poxon, J. Domke, T. Gamblin, "Towards Collaborative Continuous Benchmarking for HPC," in Proceedings of the First International Workshop on HPC Testing and Evaluation of Systems, Tools, and Software (HPCTESTS@SC'23), Denver, CO, USA, November 17, 2023. | |
|
F. Antici, K. Yamamoto, J. Domke, Z. Kiziltan, "Augmenting ML-based Predictive Modelling with NLP to Forecast a Job's Power Consumption," in Proceedings of the 1st International Workshop on the Environmental Sustainability of High-Performance Software (SHiPS@SC'23), Denver, CO, USA, November 12, 2023. | |
|
R. Barton, M. Wahib, J. Domke, I.R. Ivanov, L. Zhang, S. Matsuoka, "BITFLEX - An HPC User-Driven Automatic Toolchain for Precision Manipulation and Approximate Computing," Poster presented at ISC High Performance 2023, ISC '23, Hamburg, Germany, May 2023. | |
|
S. Matsuoka, J. Domke, M. Wahib, A. Drozd, T. Hoefler, "Myths and Legends in High-Performance Computing," in The International Journal of High Performance Computing Applications, IJHPCA, vol. 0, pp. 15, April 2023. | |
|
E. Vatai, J. Domke, B. Gerofi, Y. Kodama, M. Wahib, A. Podobas, S. Mittal, M. Pericas, L. Zhang, P. Chen, A. Drozd, S. Matsuoka, "Quantifying the Effects of Copious 3D-Stacked Cache on HPC Workloads," Poster presented at IEEE Symposium on Low-Power and High-Speed Chips and Systems, COOL Chips 26, Tokyo, Japan, April 2023. | |
|
W.S. Moses, I.R. Ivanov, J. Domke, T. Endo, J. Doerfert, O. Zinenko, "High-Performance GPU-to-CPU Transpilation and Optimization via High-Level Parallel Constructs," in Proceedings of the 28th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, PPoPP '23, (New York, NY, United States), Association for Computing Machinery, Feb. 2023. | |
|
I.R. Ivanov, W.S. Moses, J. Domke, T. Endo, "Parallel Optimizations and Transformations of GPU Kernels Using a High-Level representation in MLIR/Polygeist," Poster presented at IEEE/ACM International Symposium on Code Generation and Optimization, CGO 2023, Montreal, Canada, Feb. 2023. |
|
W.S. Moses, I.R. Ivanov, J. Domke, T. Endo, J. Doerfert, O. Zinenko, "High-Performance GPU-to-CPU Transpilation and Optimization via High-Level Parallel Constructs," Poster presented at 2022 LLVM Developers' Meeting, San Jose, USA, Nov. 2022. | |
|
S. Matsuoka, J. Domke, "Life after Fugaku—What Have We Learned and How Do We Proceed as the End of Moore's Law Approaches?," in SIAM News (not peer-reviewed), Society for Industrial and Applied Mathematics, Sept. 2022. | |
|
T.N. Truong, F. Trahay, J. Domke, A. Drozd, E. Vatai, J. Liao, M. Wahib, B. Gerofi, "Why Globally Re-shuffle? Revisiting Data Shuffling in Large Scale Deep Learning," in Proceedings of the 36th IEEE International Parallel & Distributed Processing Symposium (IPDPS), (Lyon, France), IEEE Computer Society, May 2022. | |
|
S. Matsuoka, J. Domke, M. Wahib, A. Drozd, R. Bair, A.A. Chien, J.S. Vetter, J. Shalf, "Preparing for the Future—Rethinking Proxy Applications," in Computing in Science & Engineering (CiSE), vol. 24, no. 2, May 2022. | |
|
I.R. Ivanov, J. Domke, T. Endo, "Automatic translation of CUDA code into high performance CPU code using LLVM IR transformations," Poster presented at The 4rd R-CCS International Symposium (RCCS-IS4), Kobe, Japan, Feb. 2022. |
|
S. Farrell, M.Emani, J. Balma, L. Drescher, A. Drozd, A. Fink, G. Fox, D. Kanter, T. Kurth, P. Mattson, D. Mu, A. Ruhela, K. Sato, K. Shirahata, T. Tabaru, A. Tsaris, J. Balewski, B. Cumming, T. Danjo, J. Domke, T. Fukai, N. Fukumoto, T. Fukushi, B. Gerofi, T. Honda, T. Imamura, A. Kasagi, K. Kawakami, S. Kudo, A. Kuroda, M. Martinasso, S. Matsuoka, H. Mendonça, K. Minami, P. Ram, T. Sawada, M. Shankar, T.S. John, A. Tabuchi, V. Vishwanath, M. Wahib, M. Yamazaki, J. Yin, "MLPerf HPC: A Holistic Benchmark Suite for Scientific Machine Learning on HPC Systems," in Proceedings of the 7th IEEE/ACM Workshop on Machine Learning in High Performance Computing Environments (MLHPC@SC'21) 2021, St. Louis, MO, USA, November 15, 2021. | |
|
J. Domke, "A64FX – Your Compiler You Must Decide!," in Proceedings of the 2021 IEEE International Conference on Cluster Computing (CLUSTER), EAHPC Workshop, (Portland, Oregon, USA), IEEE Computer Society, Sept. 2021. | |
|
J. Domke, E. Vatai, A. Drozd, P. Chen, Y. Oyama, L. Zhang, S. Salaria, D. Mukunoki, A. Podobas, M. Wahib, S. Matsuoka, "Matrix Engines for High Performance Computing: A Paragon of Performance or Grasping at Straws?," in Proceedings of the 35th IEEE International Parallel & Distributed Processing Symposium (IPDPS), (Portland, Oregon, USA), IEEE Computer Society, May 2021. | |
|
M. Besta, J. Domke, M. Schneider, M. Konieczny, S.D. Girolamo, T. Schneider, A. Singla, T. Hoefler, "High-Performance Routing with Multipathing and Path Diversity in Supercomputers and Data Centers," IEEE Transactions on Parallel and Distributed Systems, vol. 32, no. 4, pp. 943-959, 2021. | |
|
I.R. Ivanov, J. Domke, A. Nomura, T. Endo, "Improved failover for HPC interconnects through localised routing restoration," Poster presented at The 3rd R-CCS International Symposium (RCCS-IS3), Kobe, Japan, Feb. 2021. |
|
M. Wahib, H. Zhang, T.T. Nguyen, A. Drozd, J. Domke, L. Zhang, R. Takano, S. Matsuoka, "Scaling Distributed Deep Learning Workloads beyond the Memory Capacity with KARMA," in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC ’20, (Piscataway, NJ, USA), IEEE Press, Nov. 2020. | |
|
T. Dey, K. Sato, B. Nicolae, J. Guo, J. Domke, W. Yu, F. Cappello, K. Mohror, "Optimizing Asynchronous Multi-level Checkpoint/Restart Configurations with Machine Learning," in Proceedings of the 2020 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), May 2020. (co-located with 34th IEEE IPDPS) | |
|
K. Sato, A. Kuroda, K. Minami, J. Domke, A. Drozd, M. Wahib, S. Kudo, T. Imamura, K. Kumahata, K. Nitadori, K. Ando, S. Matsuoka, "DL4Fugaku: Deep learning for Fugaku – Scalability Performance Extrapolation," Poster presented at The 2nd R-CCS International Symposium (RCCS-IS2), Kobe, Japan, Feb. 2020. | |
|
J. Domke, K. Sato, M. Kondo, "Counter-based Performance Extrapolation Toolchain – How far can we look into the Future?," Poster presented at The 2nd R-CCS International Symposium (RCCS-IS2), Kobe, Japan, Feb. 2020. |
|
J. Domke, S. Matsuoka, I.R. Ivanov, Y. Tsushima, T. Yuki, A. Nomura, S. Miura, N. McDonald, D.L. Floyd, N. Dube, "HyperX Topology: First at-scale Implementation and Comparison to the Fat-Tree," in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC ’19, (Piscataway, NJ, USA), IEEE Press, Nov. 2019. | |
|
R. Roy, K. Sato, J. Guo, J. Domke, W. Yu, T. Hatsui, Y. Joti, "Improving Data Compression with Deep Predictive Neural Network for Time Evolutional Data," Poster presented at the International Conference for High Performance Computing, Networking, Storage and Analysis, SC ’19, (Piscataway, NJ, USA), IEEE Press, Nov. 2019. | |
|
T. Dey, K. Sato, J. Guo, B. Nicolae, J. Domke, W. Yu, F. Cappello, K. Mohror, "Optimizing Asynchronous Multi-Level Checkpoint/Restart Configurations with Machine Learning," Poster presented at the International Conference for High Performance Computing, Networking, Storage and Analysis, SC ’19, (Piscataway, NJ, USA), IEEE Press, Nov. 2019. | |
|
J. Domke, S. Matsuoka, I.R. Ivanov, Y. Tsushima, T. Yuki, A. Nomura, S. Miura, N. McDonald, D.L. Floyd, N. Dube, "The First Supercomputer with HyperX Topology: A Viable Alternative to Fat-Trees?," peer-reviewed short paper presented at the 2019 IEEE 26th Symposium on High-Performance Interconnects (HOTI 26), Aug. 2019. | |
|
J. Domke, K. Matsumura, M. Wahib, H. Zhang, K. Yashima, T. Tsuchikawa, Y. Tsuji, A. Podobas, S. Matsuoka, "Double-precision FPUs in High-Performance Computing: an Embarrassment of Riches?," in Proceedings of the 33th IEEE International Parallel & Distributed Processing Symposium (IPDPS), (Rio de Janeiro, Brazil), IEEE Computer Society, May 2019. |
|
S. Smith, C. Cromey, D.K. Lowenthal, J. Domke, N. Jain, J.J. Thiagarajan, A. Bhatele, "Mitigating Inter-Job Interference Using Adaptive Flow-Aware Routing," in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC ’18, (Piscataway, NJ, USA), IEEE Press, Nov. 2018. Best student paper finalist. | |
|
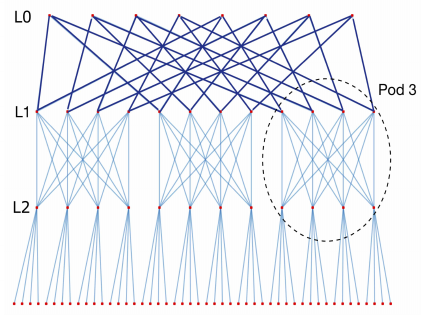
H. Bhatia, N. Jain, A. Bhatele, Y. Livnat, J. Domke, V. Pascucci, and P.-T. Bremer, "Interactive Investigation of Traffic Congestion on Fat-Tree Networks Using TREESCOPE," Computer Graphics Forum, vol. 37, no. 3, pp. 561–572, 2018. |
|
M. Mubarak, N. Jain, J. Domke, N. Wolfe, C. Ross, K. Li, A. Bhatele, C. D. Carothers, K. L. Ma, and R. B. Ross, "Toward Reliable Validation of HPC Interconnect Simulations," in Proceedings of the 2017 Winter Simulation Conference, WSC ’17, (Las Vegas, NV, USA), p. 15, IEEE Press, Dec. 2017. | |
|
J. Domke "Routing on the Channel Dependency Graph: A New Approach to Deadlock-Free, Destination-Based, High-Performance Routing for Lossless Interconnection Networks," at Technische Universität Dresden, Dresden, Germany, June 2017. Dissertation. | |
|
N. Wolfe, M. Mubarak, N. Jain, J. Domke, A. Bhatele, C. D. Carothers, and R. B. Ross, "Preliminary Performance Analysis of Multi-rail Fat-tree Networks," in 17th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing, CCGrid ’17, (Madrid, Spain), pp. 258–261, IEEE Press, May 2017. Short paper. |
|
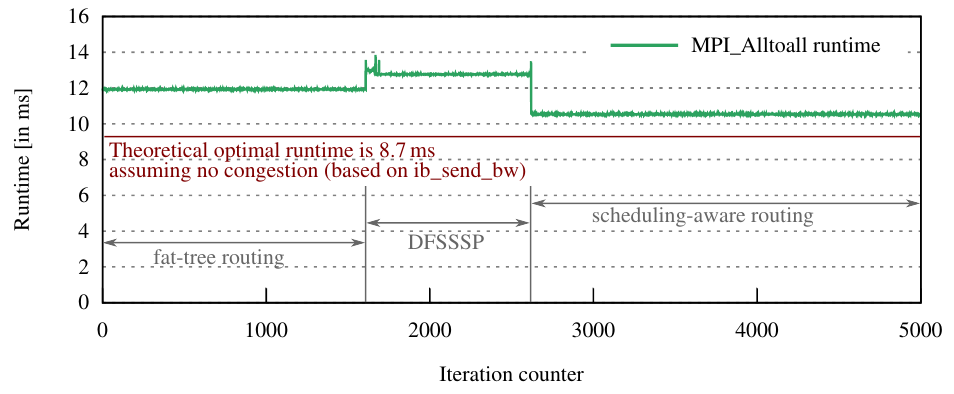
J. Domke and T. Hoefler, "Scheduling-Aware Routing for Supercomputers," in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC ’16, (Piscataway, NJ, USA), pp. 13:1-13:12, IEEE Press, 2016. | |
|
J. Domke, T. Hoefler, and S. Matsuoka, "Routing on the Dependency Graph: A New Approach to Deadlock-Free High-Performance Routing," in Proceedings of the 25th ACM International Symposium on High-Performance Parallel and Distributed Computing, HPDC ’16, (New York, NY, USA), pp. 3-14, ACM, 2016. | |
|
D. Wang, J. Domke, J. Mao, X. Shi, and D. M. Ricciuto, "A scalable framework for the global offline community land model ensemble simulation," in International Journal of Computational Science and Engineering, vol. 12, pp. 73-85, Feb. 2016. |
|
K. A. Brown, J. Domke, and S. Matsuoka, "Hardware-Centric Analysis of Network Performance for MPI Applications," in 21st IEEE International Conference on Parallel and Distributed Systems, ICPADS 2015, Melbourne, Australia, December 14-17, 2015, pp. 692-699, 2015. | |
|
J. Domke, "Increasing Fabric Utilization with Job-Aware Routing," 2015. Poster presented at International Conference for High Performance Computing, Networking, Storage and Analysis (SC ’15). |
|
K. A. Brown, J. Domke, and S. Matsuoka, "Tracing Data Movements within MPI Collectives," Poster presented at 21st European MPI Users' Group Meeting (EuroMPI/ASIA ’14). | |
|
J. Domke, T. Hoefler, and S. Matsuoka, "Fail-in-place Network Design: Interaction Between Topology, Routing Algorithm and Failures," in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC ’14, (Piscataway, NJ, USA), pp. 597-608, IEEE Press, 2014. |
|
J. Domke and D. Wang, "Runtime Tracing of the Community Earth System Model: Feasibility Study and Benefits," Procedia Computer Science, vol. 9, pp. 1950-1958, 2012. Proceedings of the International Conference on Computational Science, ICCS 2012. | |
|
R. Graham, O. Hernandez, C. Kartsaklis, J. Ladd, J. Domke, J.-C. Vasnier, S. Bihan, and G.-E. Moulard, "Third Party Tools for Titan," in Proceedings of the Cray User Group Meeting (CUG 2012), Stuttgart, Germany, Apr. 2012. Unrefereed Manuscript. | |
|
J. Domke, T. Hoefler, and W. E. Nagel, "Deadlock-Free Oblivious Routing for Arbitrary Topologies," in Proceedings of the 25th IEEE International Parallel & Distributed Processing Symposium (IPDPS), (Washington, DC, USA), pp. 613-624, IEEE Computer Society, May 2011. | |
|
J. Mueller, T. Schneider, J. Domke, R. Geyer, M. Haesing, T. Hoefler, S. Hoehlig, G. Juckeland, A. Lumsdaine, M. Mueller, and W. Nagel, "Cluster Challenge 2008: Optimizing Cluster Configuration and Applications to Maximize Power Efficiency," in Proceedings of the 10th LCI International Conference on High-Performance Clustered Computing, Mar. 2009. LCI’09 2nd Best Paper Award. |
Invited Talks
|
J. Domke "RiVault A Secure AI Infrastructure for Scientific Computing and General-purpose Applications at RIKEN" in JAPAN SCIENTIST AI JAM SESSION 2025, Dec. 2025. | |
|
J. Domke "Secure AI Infrastructure for Scientific Computing and General-purpose Applications at RIKEN" in Trillion Parameter Consortium's 2025 All-Hands Conference, July 2025. | |
|
J. Domke "Secure and privatizes “OpenAI”-replica for RIKEN-Internal Model-serving and AI Research" in AGISリトリート2025, July 2025. | |
|
J. Domke "Unifying Framework to Enable Artificial Intelligence in HPC Workflows" in Algorithms For Multiphysics Models In The Post-Moore's Law Era – Los Alamos, June 2025. | |
|
J. Domke "RAPTOR: Numerical Profiling of Scientific Applications" in Joint Laboratory for Extreme Scale Computing (JLESC), May 2025. | |
|
J. Domke "Unifying Framework to Enable Artificial Intelligence in HPC Workflows" in International Post-Exascale Project (InPEx) Workshop, April 2025. |
|
M. Sander, J. Domke "Scientific Data Compression for Large Language Models" in Workshop: Harnessing the Power of various forms of Generative AI for Science and Engineering: The Trillion Parameter Consortium (TPC) at SupercomputingAsia (SCA2025), Mar. 2025. | |
|
F. Antici, J. Domke "Automated Detection of AI Training Jobs to Enhance Security In HPC Systems" in Workshop: Harnessing the Power of various forms of Generative AI for Science and Engineering: The Trillion Parameter Consortium (TPC) at SupercomputingAsia (SCA2025), Mar. 2025. | |
|
I. Ivanov, W. Moses, E. Vatai, T. Endo, J. Domke, O. Zinenko "Polyhedral Rescheduling of GPU Kernels To Exploit Async Memory Movement" in Ninth LLVM Performance Workshop at CGO 2025, Mar. 2025. |
|
J. Domke "FugakuNEXT: An Application Prospective" in Workshop: Co-design of Next-Generation HPC Systems for Artificial Intelligence and Mixed-Analytics, International Conference for High Performance Computing, Networking, Storage and Analysis (SC ’24), Nov. 2024. | |
|
J. Domke "Scientific Benchmarking: An update from Japan / R-CCS" in The International Post-Exascale Project (InPEx) 2024 Workshop, June 2024. | |
|
J. Domke "Updates on Efforts to Pre-train LLMs in Japan" in the Trillion Parameter Consortium (TPC) Accelerating AI for Science workshop at ISC High Performance 2024, May 2024. | |
|
I. Ivanov, J. Domke, T. Endo, J. Doerfert "Automatic Parallelization and OpenMP Offloading of Fortran" in Workshop: Joint Laboratory for Extreme-Scale Computing (JLESC16), Apr. 2024. | |
|
J. Domke "Quantifying the Effects of Copious 3D-Stacked Cache on HPC Workloads -- Our insights after half a year of gem5 simulations" at the National Center for High-performance Computing of the National Applied Research Laboratories, Taiwan, Mar. 2024. | |
|
J. Domke "Quantifying the Effects of Copious 3D-Stacked Cache on HPC Workloads -- Our insights after half a year of gem5 simulations" at CASUS - Center for Advanced Systems Understanding, Germany, Jan. 2024. | |
|
J. Domke "At the Locus of Performance: Quantifying the Effects of Copious 3D-Stacked Cache on HPC Workloads" in High Performance, Edge And Cloud (HiPEAC 2024), Jan. 2024. |
|
J. Domke "Scientific Benchmarking" in EU-ASEAN High-Performance Computing (HPC) School, Dec. 2023. | |
|
J. Domke "Advanced Architecture "Playgrounds" Past Lessons and Future Accesses of Testbeds ... an update by RIKEN R-CCS" in Birds of a Feather (BoF) at International Conference for High Performance Computing, Networking, Storage and Analysis (SC '23), Nov. 2023. | |
|
J. Domke "Do Benchmarks lead to over-engineered Systems?" in Birds of a Feather (BoF) at International Conference for High Performance Computing, Networking, Storage and Analysis (SC '23), Nov. 2023. | |
|
J. Domke "At the Locus of Performance: Quantifying the Effects of Copious 3D-Stacked Cache on HPC Workloads" in ,Modeling & Simulation Seminar and Hackathon - Japan 2023, Oct. 2023. | |
|
J. Domke "At the Locus of Performance: Quantifying the Effects of Copious 3D-Stacked Cache on HPC Workloads" in The 253rd R-CCS Cafe, Oct. 2023. | |
|
J. Domke "Performance Portability at Extreme Scale: A Dream or Reality? Ferraris can't swim: A Case against Performance Portability (...for now)" in Focus Session at ISC High Performance 2023, May. 2023. |
|
J. Domke "Scientific Benchmarking" in EU-ASEAN High-Performance Computing (HPC) School 2022 (EU-ASEAN HPC School), Dec. 2022. | |
|
J. Domke "The Road to Hell is paved with good Proxy-Apps...can Octopodes help save us?" in International Conference for High Performance Computing, Networking, Storage and Analysis (SC '22), Nov. 2022. | |
|
J. Domke "From static, one-off System Evaluation to Continuous Benchmarking ... and let's retire HPL" in International Conference for High Performance Computing, Networking, Storage and Analysis (SC '22), Nov. 2022. | |
|
J. Domke "LARC: A Case Study in Enhancing CPUs with Copious 3D-Stacked Cache" in Kaust/TokyoTech/RIKEN Seminar, Oct. 2022. | |
|
J. Domke "Octopodes A candidate to replace Mini Apps and Motifs?" in 14th JLESC Workshop, Sept. 2022. | |
|
J. Domke "LARC: A Case Study in Enhancing CPUs with Copious 3D-Stacked Cache" in NHR PerfLab Seminar, Sept. 2022. | |
|
J. Domke "Panel: Computing at Extreme Scales" in Workshop on Modeling & Simulation of Systems and Applications (ModSim 2022), Aug. 2022. | |
|
J. Domke "Co-design with Proxy-Apps: A match made in heaven?" in Workshop on Software Co-Design Actions in European Flagship HPC Codes at ISC High Performance: International Conference on High Performance Computing (ISC ’22), June 2022. | |
|
J. Domke "Working with Proxy-Applications: Interesting Findings, Lessons Learned, and Future Directions" in Measuring the Effective Performance of High-Performance Computer Systems (workshop) at ISC High Performance: International Conference on High Performance Computing (ISC ’22), June 2022. | |
|
J. Domke "Working with Proxy-Applications: Interesting Findings, Lessons Learned, and Future Directions" in HPC Solutions Forum in 37th ISC High Performance (ISC ’22), May 2022. | |
|
J. Domke "Working with Proxy-Applications: Interesting Findings, Lessons Learned, and Future Directions" in Benchmarking in the Data Center: Expanding to the Cloud (workshop) held in conjunction with PPoPP 2022: Principles and Practice of Parallel Programming 2022, April 2022. | |
|
J. Domke "MocCUDA: Running Cuda Codes on Fugaku" in SIAM Conference on Parallel Processing for Scientific Computing (SIAM PP ’22), Seattle, Washington, USA, Feb. 2022. |
|
J. Domke "The Bright Future for HPC Interconnects -- Opportunities, Challenges, and Misconceptions in Deployment and Management of Large-Scale Networks" in Focus Session: Leveraging Silicon Photonics in HPC to Meet Future Exascale Needs in 36th ISC High Performance (ISC ’21), June 2021. | |
|
J. Domke "Performance Predictions using Machine Code Analyzers" in ASTAR IHPC ACRC-Riken-CREST Deep workshop (AIARC-WS'21), May 2021. | |
|
J. Domke "Matrix Engines for High Performance Computing: A Paragon of Performance or Grasping at Straws?" in CREST Depp Meeting, April 2021. | |
|
J. Domke "Double-precision FPUs in High-Performance Computing: an Embarrassment of Riches?" in Workshop on Large-scale Parallel Numerical Computing Technology (LSPANC 2020 January), Jan. 2020. | |
|
J. Domke "First At-Scale HyperX Implementation: A Compelling Alternative to Fat-Trees?" in High Performance Consortium for Advanced Scientific and Technical Computing (HP-CAST 32), June 2019. | |
|
N. McDonald, J. Domke "Hyper-X and Next Generation Routing Engines" in High Performance Consortium for Advanced Scientific and Technical Computing (HP-CAST 31), Nov. 2018. | |
|
J. Domke "Exploring alternative Designs for HPC Interconnects and HPC Processors" in ZIH Colloquium (TU Dresden), Oct. 2018. | |
|
J. Domke "To float or not to float... How much FP64 performance do we really need?" in Workshop on Modeling & Simulation of Systems and Applications (ModSim 2018), Aug. 2018. | |
|
N. McDonald, J. Domke "HyperX and the Gen-Z optical Interconnect" in High Performance Consortium for Advanced Scientific and Technical Computing (HP-CAST 30), June 2018. | |
|
J. Domke "Routing on the Channel Dependency Graph" in 18th SIAM Conference on Parallel Processing for Scientific Computing (SIAM PP ’18), Tokyo, Japan, Mar. 2018. | |
|
J. Domke "Results from TSUBAME3.0 — A 47 AI-PFLOPS System for HPC & AI Convergence" at Omni-Path User Group (OPUG) BoF at SC ’17, Denver, Colorado, USA, Nov. 2017. (repl. for Prof Matsuoka) | |
|
J. Domke "Existing De-Facto Standards for Interconnects: InfiniBand, GigE & OmniPath" in 32th ISC High Performance (ISC ’17), Frankfurt, Germany, June 2017. |
Academic Duties
Birds of a feather at SCA/HPC Asia 2026 (Conference (Co-)chair) | |
Workshop and Tutorial at International Symposium on Code Generation and Optimization (CGO'25) (Conference (Co-)chair) | |
Architecture & Networks track at International Conference for High Performance Computing, Networking, Storage and Analysis, SC '24 (Conference (Co-)chair) | |
The 3rd R-CCS International Symposium (RCCS-IS3 (Poster (Co-)chair) | |
The Paper Is Dead. Long Live the Paper? – How LLMs Change the Field (Panel Organizer/Moderator) | |
Harnessing the Power of various forms of Generative AI for Science and Engineering: The Trillion Parameter Consortium (TPC; at SCA'25) (Workshop (Co-)chair) | |
16th JLESC Workshop (Workshop (Co-)chair for Local Arrangements) | |
28th International Workshop on High-level Parallel Programming Models and Supportive Environments (HIPS 2023 at IPDPS) (Workshop (Co-)chair) | |
Benchmarking in the Data Center: Expanding to the Cloud (BID'24 at ICPE 2024) (Workshop (Co-)chair) | |
Benchmarking in the Data Center: Expanding to the Cloud (BID'23 at PPoPP) (Workshop (Co-)chair) | |
12th Accelerated Data Analytics and Computing Institute Workshop (ADAC12) (Workshop (Co-)chair) | |
2nd International Workshop on Legacy Software Refactoring for Performance (REFAC'20) (Workshop (Co-)chair) | |
1st International Workshop on Legacy Software Refactoring for Performance (REFAC'19) (Workshop (Co-)chair) | |
Empowering Interdisciplinary Collaboration through Reproducible Benchmarking at PASC'25 (Minisymposium (Co-)organizer) | |
Minisymposium at the 18th SIAM Conference on Parallel Processing for Scientific Computing (SIAM PP'18): "Applied Graph Theory in Interconnection Network Design and Operation" (Workshop (Co-)chair) | |
Heterogeneous Computing (at SCA/HPCAsia 2026) (BoF (Co-)organizer | |
BoF: Advanced Architecture "Playgrounds" - Past Lessons, Current and Future Accesses of Testbeds (at SC'25) (BoF (Co-)Organizer) | |
BoF: Advanced Architecture "Playgrounds" - Past Lessons, Current and Future Accesses of Testbeds (at SC'24) (BoF (Co-)Organizer) | |
BoF: Advanced Architecture "Playgrounds" - Past Lessons, Current and Future Accesses of Testbeds (at SC'23) (BoF (Co-)Organizer) |
International Conference for High Performance Computing, Networking, Storage and Analysis, SC '26 | |
International Conference for High Performance Computing, Networking, Storage and Analysis, SC '25 | |
"General Volunteer" program at International Conference for High Performance Computing, Networking, Storage and Analysis, SC '24 | |
International Conference for High Performance Computing, Networking, Storage and Analysis, SC '23 | |
International Conference for High Performance Computing, Networking, Storage and Analysis, SC '21 | |
ACM International Conference on Supercomputing (ICS) 2026 | |
ACM International Conference on Supercomputing (ICS) 2024 | |
Supercomputing Asia and International Conference on High Performance Computing in Asia Pacific Region (SCA/HPCAsia 2026) | |
IEEE Hot Interconnects symposium (HotI’2025) | |
23rd ACM International Conference on Computing Frontiers (CF'26) | |
22nd ACM International Conference on Computing Frontiers (CF'25) | |
IEEE International Conference on Cluster Computing (CLUSTER) 2025 | |
IEEE International Conference on Cluster Computing (CLUSTER) 2024 | |
IEEE International Conference on High Performance Computing, Data and Analytics (HiPC), 2024 | |
IEEE International Conference on High Performance Computing, Data and Analytics (HiPC), 2023 | |
23rd IEEE/ACM International Symposium on Cluster, Cloud and Internet Computing (CCGRID 2023) | |
35th ACM International Symposium on High-Performance Parallel and Distributed Computing (HPDC '26) | |
34nd International Symposium on High-Performance Parallel and Distributed Computing (HPDC '25) | |
32nd International Symposium on High-Performance Parallel and Distributed Computing (HPDC '23) | |
31st International Symposium on High-Performance Parallel and Distributed Computing (HPDC '22) | |
39th IEEE International Parallel & Distributed Processing Symposium (IPDPS'25) | |
38th IEEE International Parallel & Distributed Processing Symposium (IPDPS'24) | |
37th IEEE International Parallel & Distributed Processing Symposium (IPDPS'23) | |
36th IEEE International Parallel & Distributed Processing Symposium (IPDPS'22) | |
International Conference on High Performance Computing in Asia-Pacific Region (HPC Asia 2020) | |
53th International Conference on Parallel Processing (ICPP 2024) | |
51th International Conference on Parallel Processing (ICPP 2022) | |
46th International Conference on Parallel Processing (ICPP 2017) | |
Parallel AI and Systems for the Edge (PAISE 2024; at IPDPS'24) | |
Second International Workshop on HPC Testing and Evaluation of Systems, Tools, and Software (HPCTESTS 2024; at SC'24) | |
First International Workshop on HPC Testing and Evaluation of Systems, Tools, and Software (HPCTESTS 2023; at SC'23) | |
Fifth International Workshop on Coarse-Grained Reconfigurable Architectures for High-Performance Computing (CGRA4HPC'26; at IPDPS'26) | |
Fourth International Workshop on Coarse-Grained Reconfigurable Architectures for High-Performance Computing (CGRA4HPC'25; at IPDPS'25) | |
Third International Workshop on Coarse-Grained Reconfigurable Architectures for High-Performance Computing (CGRA4HPC'24; at IPDPS'24) | |
Second International Workshop on Coarse-Grained Reconfigurable Architectures for High-Performance Computing (CGRA4HPC'23) | |
International Workshop on Arm-based HPC: Practice and Experience (IWAHPCE2026; at SCA/HPCAsia 2026) | |
International Workshop on Arm-based HPC: Practice and Experience (IWAHPCE2025; at HPCAsia'25) | |
International Workshop on Arm-based HPC: Practice and Experience (IWAHPCE2024; at HPCAsia'24) | |
International Workshop on Arm-based HPC: Practice and Experience (IWAHPCE2023; at HPCAsia'23) | |
International Workshop on Large Language Models (LLMs) and HPC (LLMxHPC 2024; at CLUSTER'24) | |
EAHPC-2022 - Embracing Arm (IEEE Cluster 2022 Workshop) | |
EAHPC-2021 - Embracing Arm (IEEE Cluster 2021 Workshop) | |
EAHPC-2020 - Embracing Arm (IEEE Cluster 2020 Workshop) | |
3rd R-CCS International Symposium (RCCS-IS3, 2021) | |
2nd R-CCS International Symposium (RCCS-IS2, 2020) | |
20th Annual OpenFabrics Alliance Workshop (OFA Workshop 2024) | |
19th Annual OpenFabrics Alliance Workshop (OFA Workshop 2023) | |
18th Annual OpenFabrics Alliance Workshop (OFA Workshop 2022) | |
17th Annual OpenFabrics Alliance Workshop (OFA Workshop 2021) | |
16th Annual OpenFabrics Alliance Workshop (OFA Workshop 2020) | |
15th Annual OpenFabrics Alliance Workshop (OFA Workshop 2019) | |
14th Annual OpenFabrics Alliance Workshop (OFA Workshop 2018) | |
5th IEEE International Workshop of High-Perfomance Interconnection Networks in the Exascale and Big-Data Era (HiPINEB 2019) | |
4th IEEE International Workshop of High-Perfomance Interconnection Networks in the Exascale and Big-Data Era (HiPINEB 2018) | |
1st International Workshop on Foundational large Language Models Advances for HPC in Asia (LLM4HPCAsia; at SCA/HPCAsia 2026) | |
1st International Workshop on Foundational large Language Models Advances for HPC (LLM4HPC; at ISC'25) | |
AI on HPC: Challenges and Opportunities (at ISC'26) |
Office of Advanced Scientific Computing Research (ASCR), Department of Energy Office of Science | |
Computing (COMP) | |
IEEE Micro | |
IEEE Transactions on Computers (TC) | |
IEEE Transactions on Parallel and Distributed Systems (TPDS) | |
IEEE Transactions on Network and Service Management | |
Data in Brief (DIB) | |
Journal of King Saud University - Computer and Information Sciences (JKSU-CIS) | |
Journal of Parallel and Distributed Computing (JPDC) | |
Parallel Computing (PARCO) | |
Institute of Electronics, Information and Communication Engineers (IEICE) | |
ACM Symposium on High-Performance Parallel and Distributed Computing (HPDC) | |
IEEE International Conference on Parallel and Distributed Systems (ICPADS) | |
IEEE International Parallel & Distributed Processing Symposium (IPDPS) | |
IFIP International Conference on Network and Parallel Computing (NPC) | |
International Conference for High Performance Computing, Networking, Storage and Analysis (SC) | |
International Conference on Supercomputing (ICS) | |
International European Conference on Parallel and Distributed Computing (Euro-Par) | |
International Journal of High Performance Computing Applications (IJHPCA) | |
IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems (TCAD) | |
Microprocessors and Microsystems (MICPRO) |





For established Researchers and Postdocs
[Click here for our Job Postings] The Supercomputing Performance Research Team conducts performance studies of traditional HPC architectures and software subsystems such as processors, networks, memory, accelerators, and storage; and the team investigates non-traditional hardware, such as neuromorphic chips, optical processors, and quantum computing devices to analyze their applicability to speed up supercomputing workloads. The team’s mission is to improve the performance, efficiency, and usability of Fugaku and upcoming supercomputers by data-driven co-design.
The scientist will join a vibrant team and top-class HPC institute to collaborate with other computer science and domain science teams to conduct research on HPC performance, such as performance modeling, simulation, prediction, and monitoring, in order to enhance the community’s understanding of cutting-edge and future supercomputers as well as applications running on these systems. Furthermore, the scientist will be in charge of benchmark design and preservation of existing benchmark suites to conduct short-term analysis of various systems and long-term tracking of performance trends.
[Click here for SPDR Program] There is a pressing need to make the most of creative and basic research potential if we are to pioneer new frontiers in science and technology on a global scale. And for this our greatest hope lies with the work of talented and free-thinking young scientists. RIKEN's program for Special Postdoctoral Researchers (SPDR) was instituted to provide young and creative scientists the opportunity to be involved in autonomous and independent research that is in line with RIKEN objectives and research fields.
Join our team as Student / Intern
RIKEN Internship options for Internation and Domestic Students (contact me for more information):
- RIKEN R-CCS Internship Program (short-term) for undergraduate & graduate students of Japanese universities [details]
- International Program Associate (long-term) for PhD students enrolled in partnering universities[details]
- Junior Research Associate Program (long-term) for PhD students enrolled in Japanese universities[details]
- RIKEN International HPC Spring School 2024 - Toward Society 5.0 (3-days intensive training and networking) [details]
- 2025 APAC HPC-AI Competition[details]
- 2026 ACM Asian School on High-Performance Computing and Artificial Intelligence[details]
- ...above categories don't fit? Then contact me and we find a solution!
Current and previous Students
(Co-)Supervisor for PhD Thesis:
- Ivan R. Ivanov, RIKEN Junior Research Associate (JRA), 2023–2026, Tokyo Tech, "Compiler-Driven Performance Portability for Heterogeneous High-Performance Computing"
(Co-)Supervisor for Master's Thesis:
- Ivan R. Ivanov, 2023, Tokyo Tech, "Optimizations and Transformations of Parallel Code via High Level Intermediate Representation"
- Kevin A. Brown, 2014, Tokyo Tech, "Identifying Network Bottlenecks within MPI Collectives"
(Co-)Supervisor for Bachelor's Thesis:
- Nils Blach, 2021, ETH Zürich, "Multipath Routing for Low-Diameter Network Topologies on InfiniBand Architecture"
- Ivan R. Ivanov, 2021, Tokyo Tech, "Improved failover for HPC interconnects through localised routing restoration"
- J. Bokstaller, 2019, ETH Zürich, "Design and Implementation of Multipath Switching in InfiniBand Slimfly Networks"
RIKEN Internship Students, Remote Trainees, and Research Fellows:
- Tamao Takahashi, 2025
- Michail Boulasikis, 2025
- Sophia M. Herrmann, 2025 (& RT)
- Lucas B.H. Van Lanker, 2025
- Sarthak Joshi, 2025
- Bole Ma, 2025
- Niklas Bartelheimer, 2025
- Hari Abram, 2024–2025 (& RT)
- Maximilian Sanders, 2024–2025 (& RF)
- Joao Batista Fernandes, 2024
- Gianmarco Accordi, 2024
- Jingde Zhou, 2024
- Nils Blach, 2023
- Clement Gavoille, 2023
- Faveo Hoerold, 2023–2025 (& RT)
- David Mendelsohn, 2023
- Linwei Jiang, 2023
- Ke Fan, 2023–2025 (& RT)
- Francesco Antici, 2023–2024 (& RT)
- Semih Burak, 2023
- Gia Huy Trinh, 2023
- Ivan R. Ivanov, 2020–2023
- Kohei Sugihara, 2020
- Tonmoy Day & Rupak Roy, 2019
Teaching at TU Dresden (discontinued)
Courses in Winter Semester 2016/2017: Ø
Courses in summer semester 2016:
- Rechnerarchitektur II (Exercises)
- Theorie und Einsatz von Verbindungseinrichtungen in parallelen Rechnersystemen
- More lectures of the Chair for Computer Architecture
Courses in Winter Semester 2015/2016: Ø
Courses in summer semester 2015:
- Rechnerarchitektur II (Exercises)
- Theorie und Einsatz von Verbindungseinrichtungen in parallelen Rechnersystemen
Courses in Winter Semester 2014/2015: Ø
About Me
Jens Domke is the Team Principal of the Supercomputing Performance Research Team at the RIKEN Center for Computational Science (R-CCS), Japan. He received his doctoral degree from the Technische Universität Dresden, Germany, in 2017 for his work on HPC routing algorithms and interconnects. Jens started his career in HPC in 2008, after he and a team of five students of the TU Dresden and Indiana University, won the Student Cluster Competition at SC08. Since then, he published dozens of peer-reviewed journal and conference articles. Jens contributed the DFSSSP and Nue routing algorithms to the subnet manager of InfiniBand, and built the first large-scale HyperX prototype at the Tokyo Institute of Technology. His research interests include system co-design, performance evaluation, extrapolation, and modelling, interconnect networks, and optimization of parallel applications and architectures.